人工智能$\supset$机器学习$\supset$深度学习
专家系统:依靠人编写足够多的规则给计算机执行,让计算机成为“专家”,计算机不具备学习能力(20世纪80年代)。属于符号主义人工智能。
机器学习的技术定义:在预先设定好的可能性空间(hypothesis space)中,利用反馈信号的指引找到输入数据的最有用表示(representation)。
什么是深度学习? 深度学习的深度(depth)不是指理解深度,而是指一些列的表示层(layer)的层数很多,这些分层几乎都是通过叫“神经网络”(neural network)的模型学习到的。(神经网络虽然灵感是来自人脑,但其实和真实的人脑学习机制并不相同,只是一种数学框架)
深度学习的基本原理:每个表示层有一个权重,预测结果与真实结果的差距用损失函数(loss function)或目标函数(objective function)衡量,一遍遍的训练循环,以损失函数的反馈调整表示层的权重,最后找到最优权重组。(BP误差反向传播算法)
- 将批量数据输入神经网络
- 计算神经网络预测值$y_{pred}$和真值$y_t$的差距(loss function)
- 运用最优化方法,如随机梯度下降法,沿梯度反方向调整权重参数
相比于SVM、决策树等浅层算法,深度学习有更多的表示层,并且可以同时学习所有表示层(贪婪学习)。现在流行的两种方法:梯度提升机和深度学习。梯度提升机用于浅层学习,处理结构化数据;深度学习则用于图像处理等感知问题。
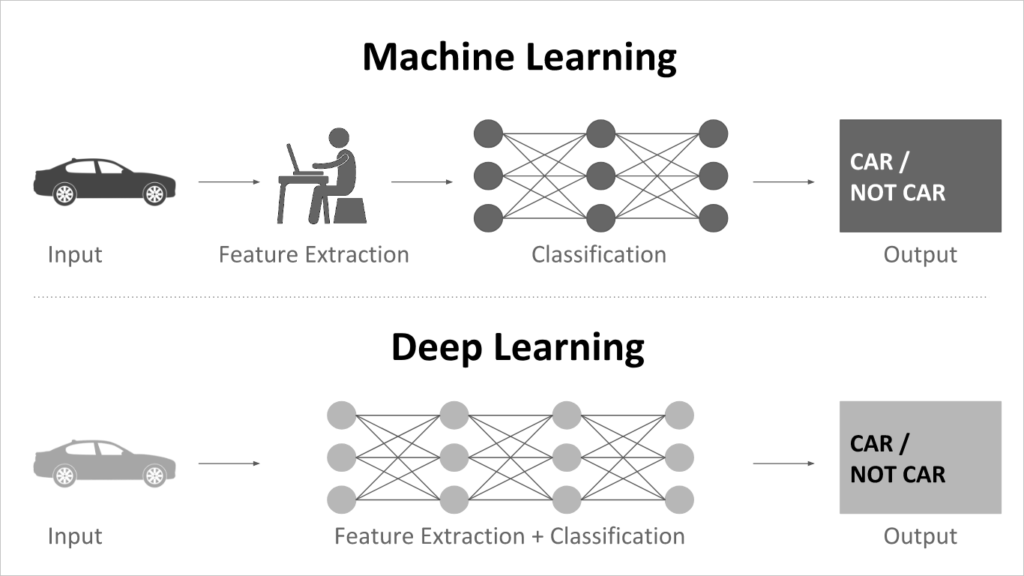
传统机器学习和深度学习的区别:传统机器学习需要人工提取特征(特征工程),再利用分类算法(SVM、决策树等)输出结果;深度学习直接端到端学习,特征提取和分类全部由神经网络完成。
神经网络基本构成
数据
深度学习中的数据张量可以有几个轴,其中0轴一般都是样本轴/批量轴,下面说明常见的数据张量可以有哪些轴。
- 2D张量:(samples,features)向量数据
- 3D张量:(samples,timesteps,features)时间序列数据或序列数据
- 4D张量:(samples,height,width,channels)图像
- 5D张量:(samples,frames,height,width,channels)视频
层
不同维度的数据张量对应输入不同的层。2D张量通常用密集连接层(dense connected layer)/全连接层(fully connected layer);3D张量通常用循环层(recurrent layer);4D张量通常用二维卷积层(如Keras的Conc2D)。
在Keras中,根据层兼容性(该层输入输出的特定张量形状),层与层可以像搭积木一样组合在一起。
模型
层构成的网络称为模型。不同的模型其实就是具有不同拓扑结构的层网络。一些常见的网络拓扑结构有:
- 线性结构:将单一输入映射为单一输出
- 双分支机构(two-branch)网络
- 多头网络(multihead)
- Inception模块
在Keras中有两种定义模型的方法:
- Sequential类(仅用于层的线性堆叠)
- 函数式API(用于层组成的有向无环图,可以构建任何形式的架构)
损失函数
选择最合适的损失函数。比如二分类问题可以选择二元交叉熵((binary cross entropy);多分类问题可以用分类交叉熵(categorical cross entropy);回归问题可以用均方误差(mean-square error)等。
优化器
优化方法的选择。
神经网络的学习算法
人工神经网络(ANN)
误差反向传播(BP)算法
利用网络的输出与期望的误差,反向调整前面各层的权重,最终可以得到一个逼近期望的神经网络(Rumelhart, McCliland 1985)。
Hopfield算法
自适应共振理论(ART)算法
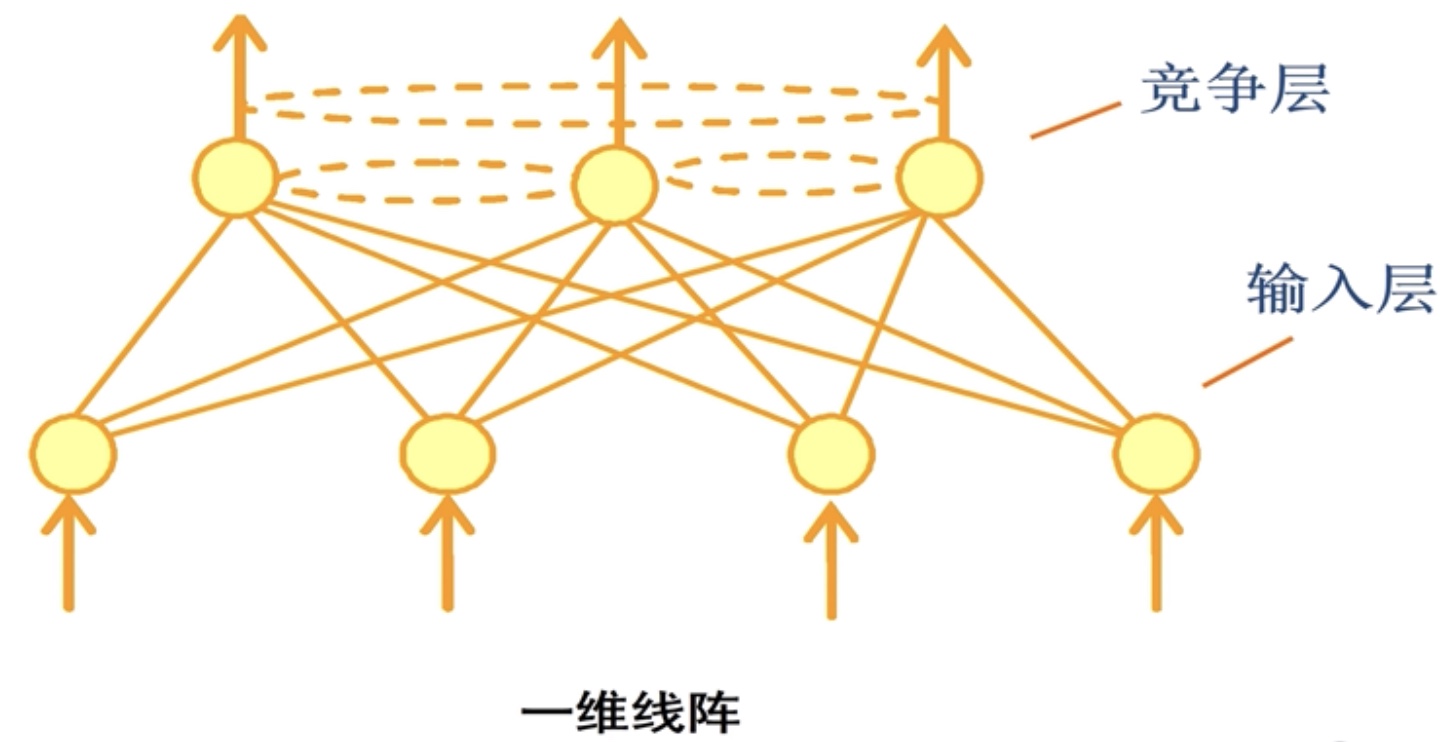
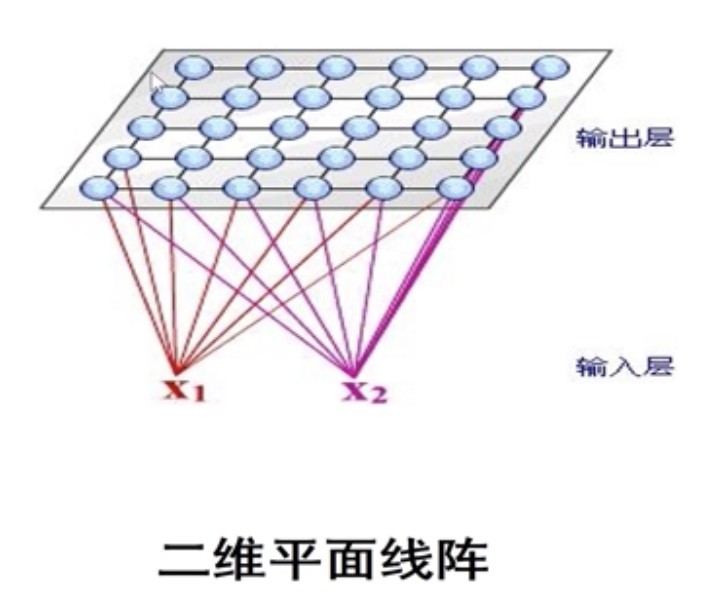
自组织映射(SOM)算法
两层拓扑结构,输入和输出层。输入可以是任意形式的,输出层(也称竞争层)一般是一维或二维的。
卷积神经网络(CNN)
卷积神经网络与普通人工神经网络相比增加了卷积层和池化层。How Convolutional Neural Networks work-Brandon Rohrer
Keras实践
准备数据
对数据预处理,有时需要标准化。
训练集、验证集和测试集
数据需要分成三份:训练集、验证集和测试集。单独留出一份测试集,而不使用验证集做最后测试的原因是:除了机器最优化过程对权重参数的“学习”,人往往还要调整模型配置(成为超参数),比如选择层数、每层的大小,这本质上也是“学习”,特别是当多次重复“以验证集评估,修改模型配置”的过程,验证集的信息会泄露到模型中。
选择模型
包括层的配置,损失函数的选择,优化器选择
验证模型
当数据集比较小时,可以考虑用K折验证的方法评估你的网络。
「过拟合的概念」
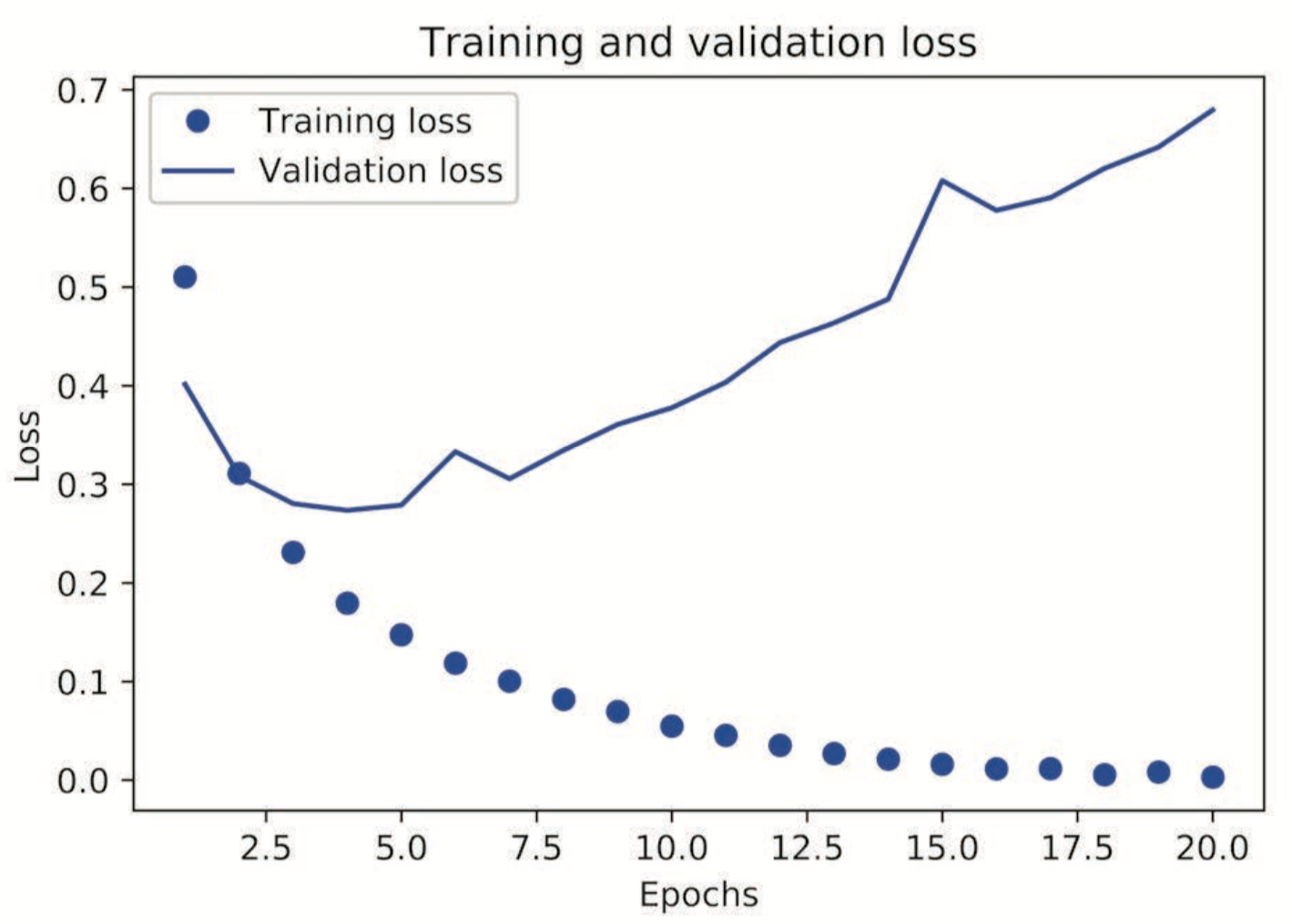
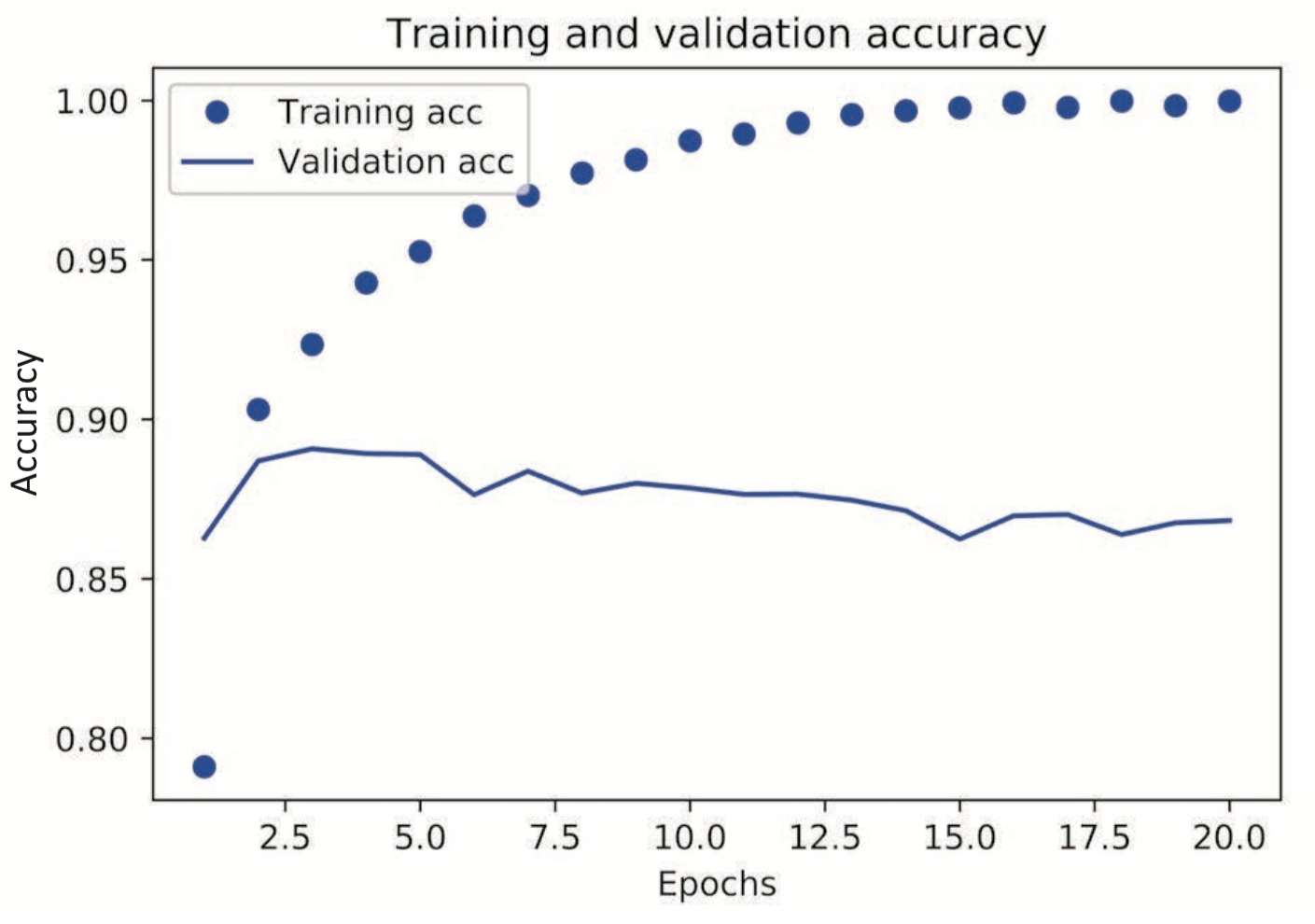
训练精度和验证精度刚开始回随着迭代次数增加而增加,但会到达一个临界点,训练精度虽然继续增加,但验证精度反而会下降,这叫做过拟合。
应用深度学习需要同时理解:
- 问题的动机和特点;
- 将大量不同类型神经网络层通过特定方式组合在一起的模型背后的数学原理;
- 在原始数据上拟合极复杂的深层模型的优化算法;
- 有效训练模型、避免数值计算陷阱以及充分利用硬件性能所需的工程技能;
- 为解决方案挑选合适的变量(超参数)组合的经验。
参考
弗朗索瓦·肖莱《Python深度学习》人民邮电出版社